
Jestem wielkim fanem mierzenia i miar wszelakich, natomiast dziś będzie o tym, dlaczego uważam, że Capacity zespołu jest złe i bardzo zwodnicze jako miara.
Tu po pierwsze zwracam uwagę, że miara, nie metryka – kudos dla Andy’ego Brandta, za wypunktowanie tego, że metryka to kalka z języka angielskiego (ang. metric) i oznacza akt stanu cywilnego – urodzenia, ślubu i zgonu 🙂 Stąd też staram się zmienić swój nawyk mówienia “metryka” w kontekście innym niż genealogia (która nawiasem mówiąc jest jedną z moich pasji). Tak więc – jeśli chodzi o mierzenie, jestem na TAK.
Jednocześnie, jestem przede wszystkim fanem MĄDREGO mierzenia. W dodatku tylko w takim zakresie, w jakim nakłady na mierzenie zwracają się, dostarczając ważnych i użytecznych danych do podejmowania mądrych decyzji. Unikam robienia albo gromadzenia miar na zapas, na zasadzie “a może się przyda”. Bo to klasyczne LEANowe marnotrawstwo (Muda) – Overproduction. Unikam także miar, które pozornie coś pokazują, ale jak spojrzeć głębiej – ich przydatność i sens mocno dyskusyjne.
I tutaj na warsztat wjeżdża miara, co do której jestem dość negatywnie nastawiony. Z jednej strony ze względu na jej powszechność, z drugiej – na jej bezsensowność i częste używane w sposób dość bezrefleksyjny 🙂
Prawdopodobnie (mój domysł!) popularność tej miary bierze się z nawiązania do pytania ze Scrum Guide’a, bezpośrednio odnoszącego się do Sprint Planningu:
What can be Done this Sprint?
Odpowiedzią na to jest między innymi to zdanie:
Selecting how much can be completed within a Sprint may be challenging. However, the more the Developers know about their past performance, their upcoming capacity, and their Definition of Done, the more confident they will be in their Sprint forecasts.
No i właśnie. Zespół powinien brać pod uwagę capacity (czyli dostępność poszczególnych członków Scrum Teamu) w nadchodzącym Sprincie. Po co? Żeby móc oszacować (zaprognozować) ile i które elementy Product Backlogu jest w stanie wykonać. W Scrumie świadomość Capacity zespołu prowadzi do pewnego celu związanego z planowaniem.
Zatem mierzenie tego wskaźnika wstecz, a zwłaszcza w postaci mniej lub bardziej skomplikowanych wyliczeń jest w tym celu NIEPOTRZEBNE. Plotka głosi, niektórzy tworzą specjalne pliki excelowe, żeby np. śledzić zmiany trendu wartości tej “miary” w czasie 😉
W dodatku niesie to ze sobą pokusę do różnorakich wyliczeń – np. w tym Sprincie zespół wykonał 1,66 Story Pointa per obecną osobę per dzień. Tayloryzm pełną gębą.
Dlatego za chwilę prześledzimy wspólnie, dlaczego skomplikowane mierzenie i wyliczanie Capacity w nadchodzącym Sprincie także nie ma sensu 🙂
Pierwsza rzecz – jaki jest najprostszy sposób liczenia dostępności osób w Sprincie?
Headcount – liczymy Capacity zespołu per ‘dusza’ 🙂
Jeśli mamy w zespole maksymalną zalecaną przez Scrum Guide liczbę członków (10) i w dwutygodniowym Sprincie, w którym nie wypadają żadne święta – mamy “do dyspozycji” 100 dni roboczych.
(2 tygodnie x 5 dni x 10 osób) = 100 MDs* *Man Day – dobra, klasyczna, Project Managerska jednostka. Zakładając niezmienny w trakcie dwóch sprintów skład zespołu scrumowego – 10 dni na osobę w Sprincie.
No i fajnie. Tylko jest jeden szkopuł. Czasem się okazuje, że nie wszyscy członkowie zespołu są w nim “na 100%”. Trudne jest życie zasobu w projekcie. To uwzględniamy to w naszych wyliczeniach.
Headcount – uwzględniamy Capacity per assignment (w %)
O ile “darmozjad”‘” Scrum Master ma pełen komfort i ma tylko 1 zespół (czyli 100% zaangażowania) taki Product Owner to ma dwa zespoły i “ogarnia” dwa równoległe produkty. Czyli mamy go na 50%.
W dodatku nasz BA (wym. “bi-ej” aka Business Analyst, czyli Analityk Biznesowy) także jest na 50%. Projektu nie stać na taką “esktrawagancję”, jak cały etat dla tej roli, więc mamy pół człowieka. Czyli teraz wzór wygląda tak:
(2 tyg. x 5 dni x (8x 1 os. + 2x 0,5 os.)) = 90 MDsCzyli Capacity zespołu to średnio 9 dni na osobę w Sprincie. Noooo, ale skoro Product Owner i BA (czet. bi-ej) są u nas na 50%, a drugie 50% realizują gdzie indziej, to tak naprawdę na 50% nie są.
Headcount – odejmujemy Context Switching Tax
Według różnych źródeł, np. tego, koszty przejścia to obniżenie o 20% produktywności przy dwóch równoległych zadaniach, oraz o dodatkowe ~20% za każde kolejne dodatkowe zadanie. Więc np. przy czterech projektach alokowanych na 25%, realnej produktywności każdy dostaje ~10%, bo: (100% – 3X20%)/4.
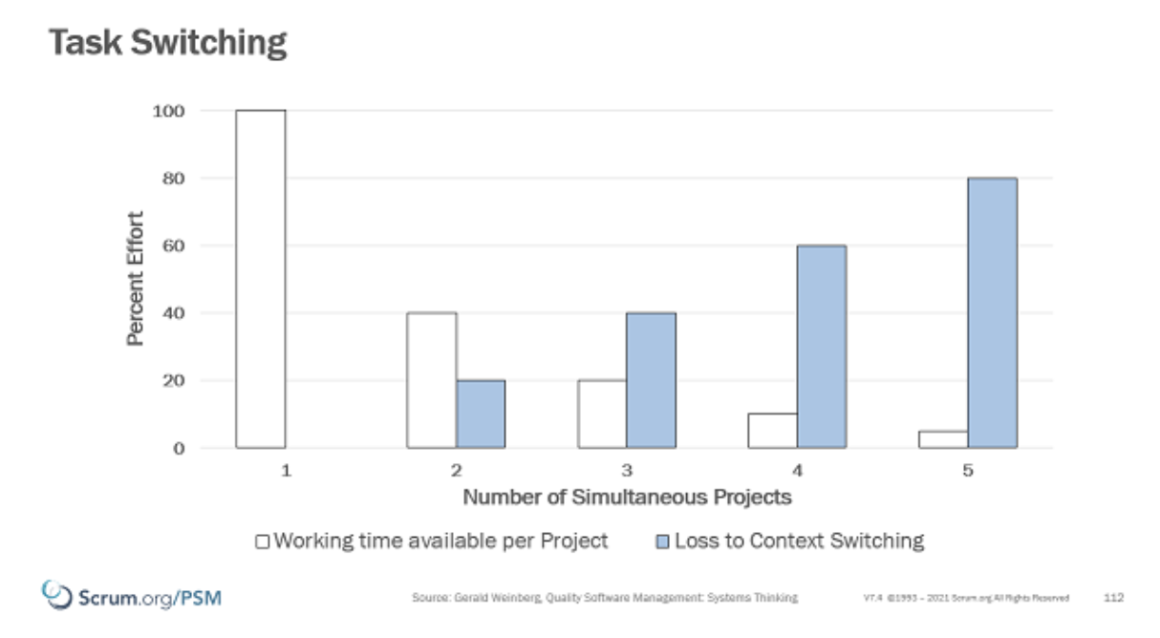

Czyli idąc tym tropem, zaktualizowany wzór wygląda tak:
(2 tyg. x 5 dni x (8x 1 os. + 2x 0,4 os.)) = 88 MDs Wychodzi 8,8 dnia na osobę w Sprincie. Takie produktywnościowe netto. Ale…
Analizując dalej, możemy się zastanowić, czy każda z osób wykonujących pracę w sprincie jest równoważna z kilku punktów widzenia, np. roli i kompetencji. I od razu instynktownie wiemy, że nie bardzo.
Headcount – Developer, czy nie Developer?
Zatem mamy teoretycznie do dyspozycji realnie produktywne 88 dni roboczych – “Man-dajsów”. Ale ale, skoro mamy w zespole SCRUMOWYM 3 role (tak, wiem, odpowiedzialności ;)), to jak to z nimi właściwie jest? Developerzy zostają jak są (przynajmniej na razie), a my liczymy dalej.
Scrum Master nie robi roboty technicznej. To po co go liczyć? Dodatkowo, przecież Product Owner najczęściej nie pracuje technicznie z Developerami. Więc może także wyłączmy go z wyliczeń.
Czyli od 88 MDs odejmujemy najpierw 10 (całość etatu Scrum Mastera) a potem jeszcze dodatkowo 4 (skoro tych 50% etatu Product Ownera nie liczyliśmy za 50%, tylko za 40%). Czyli idąc tym tropem, wzór wygląda tak:
(2 tyg. x 5 dni x (7x 1 os. + 1x 0,4 os.)) = 74 MDsTrochę mniej, zwłaszcza w porównaniu z początkową setką, ale teraz wiemy kto naprawdę pracuje w zespole 😉
Headcount – Developer, ale taki nie do końca?
Jak się dłużej przyjrzeć, to z tych Developerów też nie każdy jest równie “produktywny”, prawda? Nie każdy pisze kod. To takiego liczyć do Capacity, czy nie? Niektórzy liczą, niektórzy nie liczą. Jeden rabin powie tak, drugi rabin powie nie. I bądź tu mądry i pisz wiersze. Ale w celu pokazania ograniczeń wyliczania Capacity zespołu – nie liczymy.
Hej hej, tu (en) bi-ej?
Przecież bi-ej BA nie pracuje z nami na bieżąco nad taskami w sprincie, prawda? Przyda się na Sprint Planning, Refinement, ale przecież nie implementuje, to po co go liczyć do Capacity? To nie liczmy 🙂 Wzór bez uwzględniania testera (którego pamiętajmy mamy na 50%, a netto na 40%) wygląda teraz tak:
(2 tyg. x 5 dni x 7x 1 os.) = 70 MDsHej hej, pora tera na testera!
Skoro mamy z głowy “bi-eja”, to bierzemy się teraz za “kju-eja” (QA – Quality Assurance), zwanego potocznie (także przez niektórych Scrum Masterów) testerem. Co prawda zwanego tak niezgodnie z duchem i literą Scrum Guide’a, bo to zamiast budować poczucia jedności, buduje podział według kompetencji, ale pal licho.
I o ile Analityka Biznesowego możemy nie liczyć i nam schodzi z wyliczeń i raczej nic wielkiego się nie stanie 😉 to z testerem jest jednak gorzej.
To może połóweczka?
Znów teoretycznie, takiego testera to też możemy nie liczyć, bo i tak przez pół sprintu najczęściej “tylko” siedzi i czeka na to, co napiszą Developerzy, żeby powytykać błędy. Więc w sumie na liczbę napisanych linii kodu albo dodanych nowych funkcji bezpośrednio nie wpływa. Ale na to czy dostarczymy coś w Sprincie już czasem tak.
Więc jeśli pół Sprintu “siedzi”, to liczyć jego/jej capacity jako połowę? Czyli wyliczenie będzie wyglądać tak:
(2 tyg. x 5 dni x (6x1 os. + 1x0,5 os.)) = 65 MDsNoo ok, ale co jeśli dany PBI to w sumie z samego testowania się składa? Sam widziałem przykład zespołu, w którym dodanie funkcjonalności trwało niewiele ponad tydzień. Po czym testowano tę funkcjonalność przez ponad trzy miesiące. Czyli ponad 4 sprinty (bo tamten zespół pracował w trzytygodniowych Sprintach).
A może jednak jakieś procenty?
A może… do Capacity zespołu policzyć taki procent Testera, jaki procent PBIów z Sprincie wymaga testowania? Czyli jak zespół oceni (Tylko w sumie gdzie ma oceniać? Na Sprint Planningu? Na Refinemencie?), że w bieżącym Sprincie testowania wymaga 65% PBIów to liczymy QA x0,65, a jak w następnym wyjdzie 35%, to przemnożymy QA x0,35? Tutaj wchodzi nam do naszego wzoru dodatkowa zmienna w Excelu (no bo przecież gdzie? :))
(2 tyg. x 5 dni x (6x1 os. + 1x (Y*) os)) = ~60-70 MDs - Tutaj współczynnik Y zawiera się w przedziale: 0 <= Y <=1, bo w skrajnych przypadkach testowania może nie wymagać żaden PBI, albo mogą wymagać wszystkie. A pewnie będzie gdzieś coś pomiędzy. W sumie to też możemy liczyć i uśredniać, prawda? 😉
Ooookej, ale co jak zespół nie ma testera (Developera testującego ^^), a testy trzeba wykonać i muszą to robić Developerzy kodzący (“Frontendzi” i “Backendzi”)? To liczymy ich jako 1,0 Developera ORAZ te dajmy na to – 0,35 testera? Trochę głupio bez nadgodzin, bo to nam daje capacity tejże jednostki w wymiarze >1)
To może policzymy jakieś współczynniki ważone? Czyli np. 0,65 X Dev + 0,35 X test? Robi się coraz ciekawiej, więc zostawmy może kwestię capacity testera nierozstrzygniętą. Pojawiają się nam dodatkowe suwaczki, które odpowiednio przesunięte pozwalają nam precyzyjnie wyliczyć Capacity zespołu w nadchodzącym Sprincie. Znów 60 MDs, ale proporcje inne
(2 tyg. x 5 dni x (4x 1,0 + 3x 0,65 os. + 3x (0,35) os)) = 70 MDs W sumie można byłoby tak samo zrobić z BAem, ale że wcześniej wycięliśmy go z wyliczeń całkiem, to niech tak zostanie – #simplicity. Bo to nie koniec.
Fasada czy oficyna, czyli frontend vs backend
W TEORII ^^ to taki kompleksowy PBIa to powinien się składać z Frontu, Backendu ORAZ testów w jednym. Ale jakże często Developerzy ładnie się dzielą (Ja Frontend, Ty Backend), żeby nie trzeba było się synchronizować w trakcie pracy.
To ile capacity tych Frontów i Backów brać do obliczeń? Całość? A jeśli dany pi-bi-aj (PBI) zawiera w sobie tylko Frontend, albo tylko Backend, to co? Kolejny współczynnik? Dobra, zostawmy w całości, nie komplikujmy 🙂
I teraz, jak już przyporządkowaliśmy współczynniki, “oczyściliśmy” Capacity z SMa, BAa, QAa, w sumie i z POsa, to co, możemy lecieć łamać liczbę Story Pointów przez dostępne capacity i wyliczyć średnią z 6 Sprintów (taki żarcik), albo…
Jakie znów ALBO?!
Ile cukru w cukrze, a Seniora w Seniorze?
Albo zastanowić się, jak wyglądają kompetencje poszczególnych Developerów. Bo przecież jeden Senior jednemu Juniorowi nierówny, prawda? No to trzeba byłoby założyć jakiś współczynnik korygujący 🙂
To co, na początek – Mid Developer to 1,0. A jak wtedy liczyć Juniora? No właśnie, Juniora kompetencyjnego czy stanowiskowego? A to nie to samo? Pal licho, to jak liczyć Juniora? Za pół Mida? Za trzy czwarte? Czy może za ćwierć?
To samo z Seniorem. Liczymy jako 1,25 Mida? Jako Półtora? A może dwóch? Załóżmuy roboczo, że: 0,5 = Junior Developer, 1,0 = Mid Developer, 1,5 = Senior Developer (można dodać 2,0 = Expert Developer).
No zaraz zaraz, wiemy dobrze, że Mid Midowi też może być nierówny 🙂 więc jak to policzyć? I czy to liczyć per zespół, czy może warto to wystandaryzować ten współczynnik w organizacji? I kto to powinien oceniać? Zespół? Przełożony? Niezależny ekspert? Wiemy jak z tą niezależnością, prawda?
To może być ten moment, o ile nie nastąpił już wcześniej, że zaczyna do nas docierać bezsensowność tego co robimy. Ale na potrzeby dzisiejszej “analizy” brnijmy dalej, ponieważ jest uświadomienie sobie i innym pewnych mechanizmów niesie dużą wartość.
Ile waży koń troja… tzn. Senior swój, a ile “obcy”? I jak bardzo jest “obcy”?
Jak (jeśli?) już mamy wystandaryzowanych Juniorów, Midów i Seniorów, to teraz wypadałoby się zastanowić nad kolejną rzeczą. No bo czy dwóch Developerów na tym samym poziomie kompetencji (zakładając, że to możliwe) można liczyć tak samo, jeśli jeden jest wysezonowany w organizacji, a drugi zaczął tydzień temu? A co jeśli nie ma części dostępów? Albo tylko jednego, ale kluczowego, np. do GitHuba?
To czy w takim razie liczyć jakiś współczynnik rozwoju dla osób nowych w organizacji? Np. pierwszy Sprint to 0,5? A dlaczego 0,5 a nie 0,3 albo 0,7? Trochę to w sumie arbitralne, zresztą w jakim czasie taki nowy pracownik nabiera “pełnej gotowości bojowej”?
To zależy.
(…)
Wiem, nie pomagam, ale dokładnie o to chodzi 🙂
Inny temat, mamy dwóch Seniorów w organizacji, ale jeden pisał moduł który właśnie zmieniamy, a drugi przez ostatnie 3 lata był w innym projekcie który stracił właśnie finansowanie, więc trafił tutaj. Więc Senior, ale nie do końca. Ale dla odmiany inny członek zespołu to Mid, ale jego konikiem jest technologia którą właśnie zaczyna poznawać reszta zespołu, więc to mu EXP podbija 🙂 to może jakiś bonus w Capacity by się przydał, nieprawdaż? Sporo tych zależności, pewnie już zapomnieliśmy o tym co było na górze 😉
Zbliża się finał!
Jak już ktoś wykonał karkołomną akcję próby obliczania tych wszelkich współczynników, zaprzęgnięcia tego w formułę excelową i może nawet komuś wyszła jakaś wartość zaokrąglona w dół do pełnych jednostek, i otarł dłonią pot z czoła, bo wreszcie ma jakąś liczbę którą może wkleić jako Capacity na nadchodzący Sprint, to mam ciekawostkę. To nie wszystko.

To daleko jeszcze, czy nie?
Bo niezależnie od tego, jaka liczba lub nawet przedział liczbowy zostanie wyliczony dla naszego zespołu w najbliższym sprincie, czy to jest jednoznaczne z tym, ile zespół jest w stanie zrobić?
No raczej nie do końca.
Bo może być tak, że ktoś w zespole właśnie zmaga się z chorobą. Własną, lub kogoś z najbliższej rodziny i ostatnie lub najbliższe kilka tygodni i miesięcy będą znacznie odbiegać od tego co sam chciałby z siebie dawać. U kogoś w związku coś się psuje, a nikt postronny nic nie wie. Ale to nie pozostaje bez wpływu na motywację oraz poziom skupienia i chęci do pracy.
Z lżejszych gatunkowo i przyjemniejszych rzeczy – ktoś może budować dom, lub remontować mieszkanie. Wtedy zarówno dostępny czas, jak i skupienie mogą być, hmmm… różne. Ktoś może być niewyspany. Bo urodziło mu się dziecko i trzeci dzień z rzędu śpi między 5 rano kiedy kolka niemowlęca odpuszcza, a 7 rano (kiedy do szkoły wstają starsze dzieci).
A potem o 9 rano Daily i znów Scrum Master będzie zawracał głowę trzema pytaniami (żarcik taki ;)). Komuś innemu kot przyniósł o 3 nad ranem żywego ptaka i wypuścił w salonie, więc mnóstwo czasu i energii zeszło na ganianie zarówno ptaka, jak i kota ganiającego ptaka.
Ktoś może być zadowolony z podwyżki i mieć dodatkową motywację. Albo odwrotnie, nie dostał obiecanej podwyżki, albo podwyżki wystarczyło na przysłowiowe waciki. Ktoś siedzi za długo w firmie, tracąc wiarę w kierunek, w jakim ona zmierza. Albo ma dość szefa, ewentualnie kogoś w zespole. W zespole jest konflikt. Ludzie się nie lubią. Ewentualnie jest duże ciśnienie z góry, z boku, czy skądkolwiek indziej. Albo ktoś inny nie do końca legalnie lub etycznie ciągnie drugi etat lub rozwija prywatny biznes w godzinach pracy.
Ja tam mogę bez końca (prawdopodobnie dlatego, że jednym z moich Working Geniuses jest Discernment), ale przez wzgląd na czytelników – zmierzam do podsumowania 🙂
Teraz już podsumowuję, serio! 🙂
Jeśli na tę prostą zdawałoby się metrykę miarę ma wpływ tak wiele czynników, czynników z których bardzo często nie zdajemy sobie sprawy, to pojawia się pytanie – czy to ma sens?
Wszystko co pół-żartem, pół-serio napisałem powyżej ma na celu refleksję na temat tego, że liczenie, mierzenie i pokazywanie trendów capacity według mnie nie dość, że może zabrać dużo czasu, to na koniec i tak okaże się, że po pierwsze, godzina godzinie, a ManDay ManDay’owi nierówny, a efekty pracy intelektualnej nie są funkcją liniową czasu spędzonego na pracy.
Więc po co to liczyć? Po co pokazywać w mniejszym lub większym (zdecydowanie!) przybliżeniu jakąś wartość, w dodatku próbując na tej podstawie wyciągać jakieś wnioski lub planować akcje.
No właśnie nie ma sensu 🙂 a jak coś nie ma sensu, to może nie warto tego robić? Bo ktoś kiedyś w prostym, ale mądrym dokumencie napisał tak:
Simplicity – the art of maximizing the amount of work not done – is essential.
Manifest for Agile Software Development (Agile manifesto)
To co zamiast tego? W sumie to samo, ale prościej 😉 odwołajmy się na chwilę do tekstu źródłowego. W takim Scrum Guide zalecane jest na Sprint Planningu wzięcie pod uwagę 3 rzeczy – dlaczego Sprint jest wartościowy, ile (według Developerów!) może zostać wykonane w Sprincie (biorąc pod uwagę dostępność członków zespołu) i jak praca zostanie wykonana.
I może warto przy prognozowaniu pracy te trzy rzeczy wziąć pod uwagę na znacznie wyższym poziomie niż wyliczanie dla Capacity zespołu współczynników typu “Story Points per ManDay”?
Z tą myślą Was zostawiam i jak zawsze – liczę na feedback 🙂
Pozdrawiam serdecznie,
Marcin







1 comment